
16
Dec
Dec
It’s been almost two months since PubCon in Las Vegas, and I’m still simmering from the Cutts keynote. While many in the industry tend to idolize him, even the most white-hat and pure among us has reason to take what he says with a grain of salt.
In the two months since his talk, of which you can find video here, there are a lot of things that I feel need clarification.
So, I submit to you: Clarifying Cutts: What He REALLY Meant
Content Farms
Long story short: Cutts said Google noticed people didn’t like content farms. People used Chrome extensions to block these farms. Google noticed parodies of content farms that appeared around the web mocking the thin, uninformative articles which were designed to manipulate the algorithm.
So Google cracked down on these sites. Hard.
Well, sort of.
wikiHow still exists. And it still appears as the first result for far too many queries.
That’s a sucky content farm if there ever was one.
Why has it not received the same fate as its content-farm peers? It still ranks highly because Google owns it, and Google is not about to demote their own product.
This is despite the fact that wikiHow consistently appears as the worst result for almost any query for which it appears. wikiHow articles exhibit a startling lack of detail and on occasion, lack any familiarity with the subject they are supposed to cover. This makes wikiHow the most annoying source of information on the web. (Although you could probably count wikiPedia and wikiHow’s close cousin eHow on that list as well).
My question is this: If I start making parody articles of wikiHow pages, will Google remove them from my SERPs? If that is what it takes, I will do it.
(Speaking of Google removing things in response to public outcry, how many of these https://www.youtube.com/watch?v=LTq8TrA3hb4 videos will it take before Google realizes a lot of people don’t like being forced to use Google +. Warning: Some totally justified but strong language in this video.)
This is what I heard from Cutts: If users do not like content farms, then Google does not like them either. However, if the content farm belongs to Google, then they do not care what the user thinks.
Apparently Google thinks if they shove their product down our throats long enough, we’ll have to swallow it. *cough* Google Plus *cough*
If Google wants web masters to respond to the “higher standard,” if would be encouraging if Google played by their own rules.
Playing by the rules doesn’t just apply to content farms. It applies to another point Matt Cutts mentioned:
Ads above the fold
I absolutely applaud not rewarding sites who put ads above the fold. It is a terrible user experience. If I have to scroll or click past ads to get to my desired content, there’s a pretty good chance I’ll leave your site. (Side note: How do so many big sites get away with making you click past a full-page advertisement before allowing you to go through to the main article? It’s probably because they are big sites, huh? I hate it.)
Ads above the fold are old news, but the mention at PubCon held particular resonance as banner ads for branded queries began testing in Google search that same weekend.
I’m pretty sure if people are searching for a branded term like “Southwest” there’s a pretty good chance they are going to click on the first organic search result, which is the homepage.
This is because people are too lazy to type in an entire address, so they let Google type it in for them. They don’t want a banner ad. They just want to go to the site and be done with it. You know people are likely going to click on the first organic result, so why show them a giant ad for the brand?
Because people might click on it and give Google money.
While an article on VentureBeat makes a great case for these ads, I think the main point here is to drive more money to Google so they can build giant floating cities.
Cutts claimed Google wants to provide the world with information as an “answer engine.” Why then does Google take up the majority of SERPs with ads? Products are not, by definition, “information.” Ads are the exact opposite of “strings, not things.”
If Google said they wanted to be the next Amazon, I would let this pass. Since they claim they want to be a source of knowledge and information for people, I find the present ratio of products vs. information unacceptable. I would not accept on a client site the amount of ads Google allows on their SERPs. Once again, I submit that Google should adhere to their own quality guidelines.
I know Google gets a lot of revenue from ads. I get it. They couldn’t make cool stuff without that revenue. But the problem is they are making some really shoddy shit. Which brings me to
The Google Neural Network
Google allegedly spends this ad revenue on computers that work on semantics (or floating cities, whatever). They take words and through a beautiful application of science as art these computers form semantic associations.
As a theorist, this tickles me. These computers practice Saussurian semantics. They establish “signs”. The “sign” is the summation of an association of a signifier with the signified.

Here is an example: The word “Moscow” means both the word “Moscow” but also a signified concept–the capital city of Russia, its most recognizable buildings, etc.
I’m in love with what Google attempts to do with signs. They try to understand all the possible signifieds associated with the signifier. They also attempt to improve the quality of their “signs”–an endeavor I totally support.
My question is this: If Google can spend so much money on computers making word associations, would it kill them to hire a linguist? Someone who understands synonyms, maybe?
Some of the so called “synonyms” that appear in search just aren’t. When I search for the band by the name of BOY (a query with inherent issues), I shouldn’t get results with “son” in the meta description and nowhere on the page. A wedding dress is almost always formal. A formal dress is not always a wedding dress. Yet Google frequently equates the two in SERPs.
Sometimes they get it really, really wrong. I wanted to test Google’s semantic abilities so, because I was listening to Infected Mushroom at the time, I searched for “how to mix sick beats”. The results went from bad to worse.
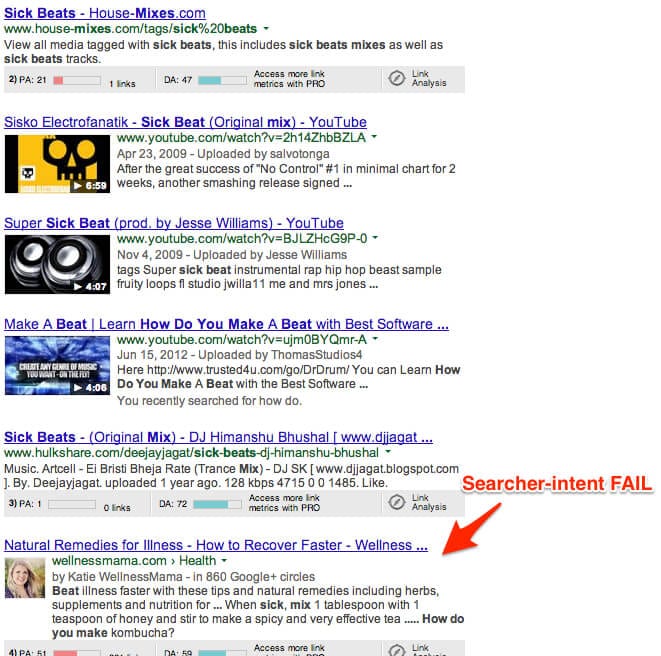
Wellness Mama is a site I have visited before. (Yes, Google has started showing you sites you’ve visited before, even if they aren’t 100% relevant to the query. That’s another post for another day). The words “beat” “mix” and “sick” all appear on the page. Besides appearing in the post, they don’t actually belong together. Like, at all. The implied “how do you make” also appears on the page, but Google ignores what comes directly after the phrase which is “kombucha” and takes you to a completely different page on the site.
In Google’s quest to avoid rewarding sites for having exact keyword phrases in a site, they still aren’t quite there with searcher intent.
They might could hire someone who actually knows about language and how it works to help them refine the intent of the ENTIRE “string.” Being fluent in your native tongue does not count as knowing about your own language.
Which brings me to
Conversational Search
Conversational search is the idea that you can ask Google a question like “How tall is Big Ben” and then ask a subsequent question about Big Ben using a pronoun like “How tall is it?” (By the way, Google claims Big Ben is 316′, which is a huge a** bell if you ask me.) In theory, Google would be able to tell the “it” refers to the Big Ben mentioned in the previous question.
So Google uses your previous search history to, hopefully, give you a more targeted answer. (Incidentally, being able to identify the antecedents of pronouns is Google’s first step towards person-hood and self-actualization. It’s only a matter of time.)
Remember the previous discussion of signs? This is just an extension of that. And the cool part? Conversational search doesn’t just apply to pronouns.
One time, I searched for “is honey gluten-free” (Don’t laugh. The store labeled the honey as “gluten-free,” and it confused me). Approximately 30 minutes later I searched “diabetes symptoms” because I had just found out Tom Hanks had diabetes.
This was the result:

So, no pronouns used. Just Google assuming they know WHY I was searching for something. Too bad for them they don’t have access to my incredibly non-sequitur brain because, for me, the searches were unrelated.
It’ll be interesting to see how this rolls out in the future. That is all.
Finally I come to
Press Release Links
During the Q&A, someone asked if they had to edit old press releases with anchor text links in them. Cutts claimed there was no need to go back and edit them.
That’s bullshit.
And I have the manual penalty messages to prove it.
That’s right. Google TOLD us a press release containing links from FOUR years ago violated the guidelines.
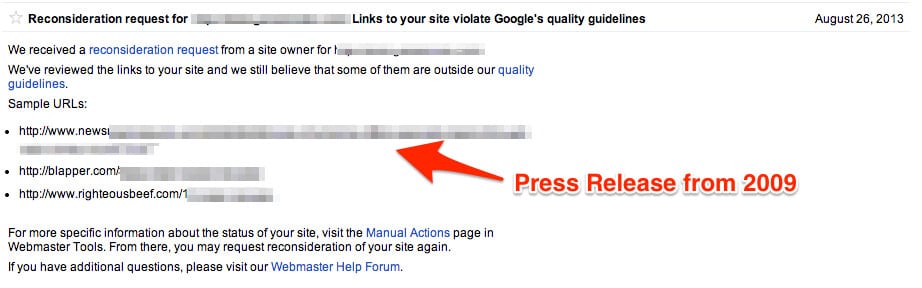
Why would the Google web spam team send such a message when Cutts said companies do not need to alter past press releases?
Because the above press release contained the three strikes of linking: too many links, with too much exact-match anchor text, on a FREE press release site.
That last strike is the worst. The client had posted the same press release on a few other sites, so why did the web spam team single out this one? It was a free site and a content dump for press releases.
How do I know the fact it was a free site made this link in particular bad? Because this press release existed on several other reputable sites where it was not removed, and the site has since had its manual penalty revoked.
Upon removing the PRs from the free–and not very reputable–sites, Google did not mention them again in subsequent messages which contained similar examples.
So the claim you do not have to remove or alter past press releases is only half true.
If you have press releases containing anchor-text links on FREE press release sites, you’d better remove that shit post haste. Think you don’t have press releases on free press release sites? Think again. Many of these sites have scraped content from paid sites like PRWeb. This was the case for our client. The site even acknowledged they had taken the content from PRWeb at the bottom of the post. Check your back links and make sure this isn’t the case for you.
If you do find one of your press releases on one of these sites, do everything you can to remove it. If you are able to remove it, great. If the site does not remove the offending links, document your efforts. If (when, more likely) the manual penalty comes, you will be prepared with documentation to show Google.
So there you have it, the things from Cutt’s presentation I believe needed clarification and/or additional insight. Have you encountered anything in your time since the Cutts speech that contradicts what he told us? Thoughts about the above? Let me know.
In the ends he always try to bring new ideas in search engine and creates a bit troublr for media marketer.